

Batch Sampler Sharding
The third (and final) way to shard your data

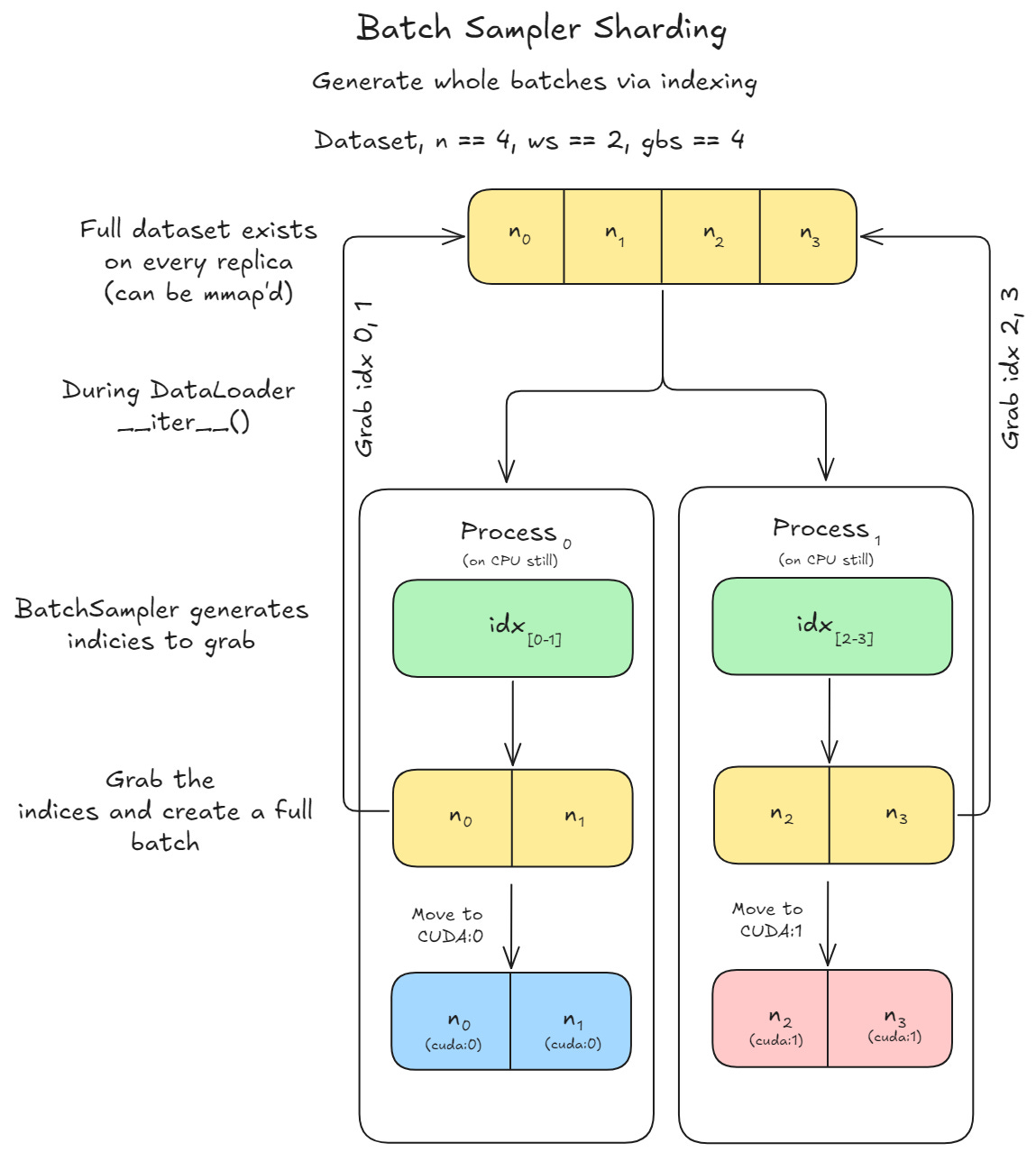
Unlike iterable dataset sharding, where each worker directly pulls raw data in its __iter__, batch sampler sharding first generates indices that specify which items to fetch. These indices are grouped into batches, which are then collated into tensors and moved to CUDA for training.
Batch sampler sharding is especially efficient when using non-trivial sampling methods (weighted, balanced, temperature-based, etc.), since the sampling logic runs once globally rather than being duplicated per worker. This ensures consistent randomness and avoids redundant computation, making it well-suited for more complex sampling strategies
On November 1st starts the second cohort of Scratch to Scale! Come learn the major tricks and algorithms used when single-GPU training hits failure points. Also get access to the prior cohort’s guest speakers too! (And get in for 35% off)